

The rapid expansion in the size and capacity of AI workloads is significantly impacting both computing and network technologies in the modern data center. Data centers are continuously evolving to accommodate higher performance GPUs and AI accelerators (XPUs), increased memory capacities, and a push towards lower latency architectures for arranging these elements. The desire for larger clusters with shorter compute times has driven heightened focus on networking interconnects, with designers embracing state-of-the-art technologies to ensure efficient data movement and communication between the components comprising the AI cloud.
A large-scale AI cloud data center can contain hundreds of thousands, or millions, of individual links between the devices performing compute, switching, and storage functions. Inside the cloud, there is a tightly ordered fabric of high-speed interconnects: webs of copper wire and glass fiber each carrying digital signals at roughly 100 billion bits per second. Upon close inspection there is a pattern and a logical ordering to each link used for every connection in the cloud, which can be analyzed by considering the physical attributes of different types of links.
For inspiration, we can look back 80 years to the origins of modern computing, when John von Neumann posed the concept of memory hierarchy for computer architectures1. In 1945 Von Neumann proposed a smaller faster storage memory placed close to the compute circuitry, and a larger slower storage medium placed further away, to enable a system delivering both performance and scale. This concept of memory hierarchy is now pervasive, with the terms “Cache”, “DRAM”, and “Flash” part of our everyday language. In today’s AI cloud data centers, we can analyze the hierarchy of interconnects in much the same way. It is a layered structure of links, strategically utilized according to their innate physical attributes of speed, power consumption, reach, and cost.
The hierarchy of interconnects
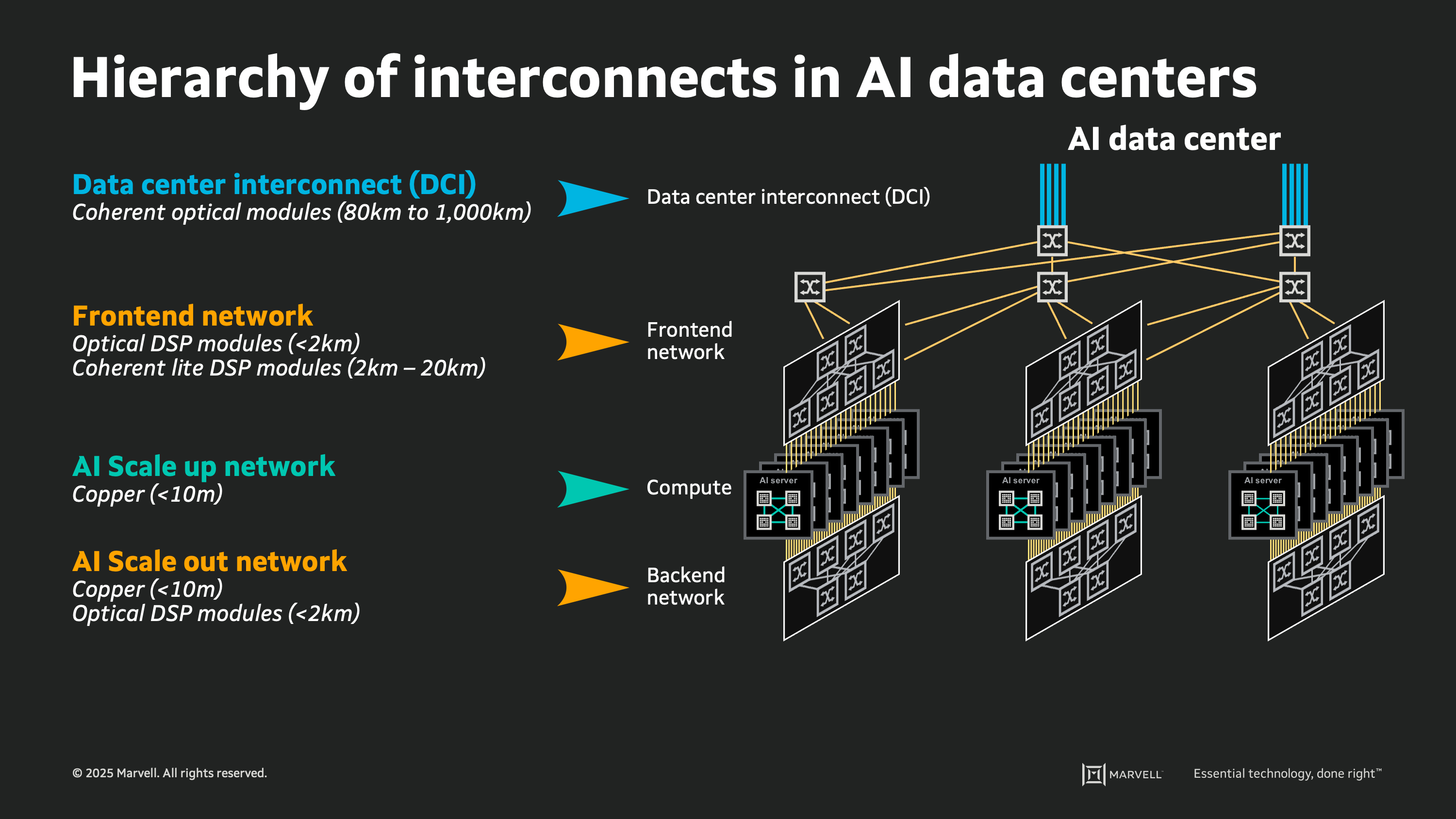
This hierarchy of interconnects provides a framework for understanding emerging interconnect technologies and to assess their potential impact in the next generation of AI data centers. Through a discussion of the basic attributes of emerging interconnect technologies in the context of the goals and aims of the AI cloud design, we can estimate how these technologies may be deployed in the coming years. By identifying the desired attributes for each use case, and the key design constraints, we can also predict when new technologies will pass the "tipping point" enabling widespread adoption in future cloud deployments.
Scale up interconnects
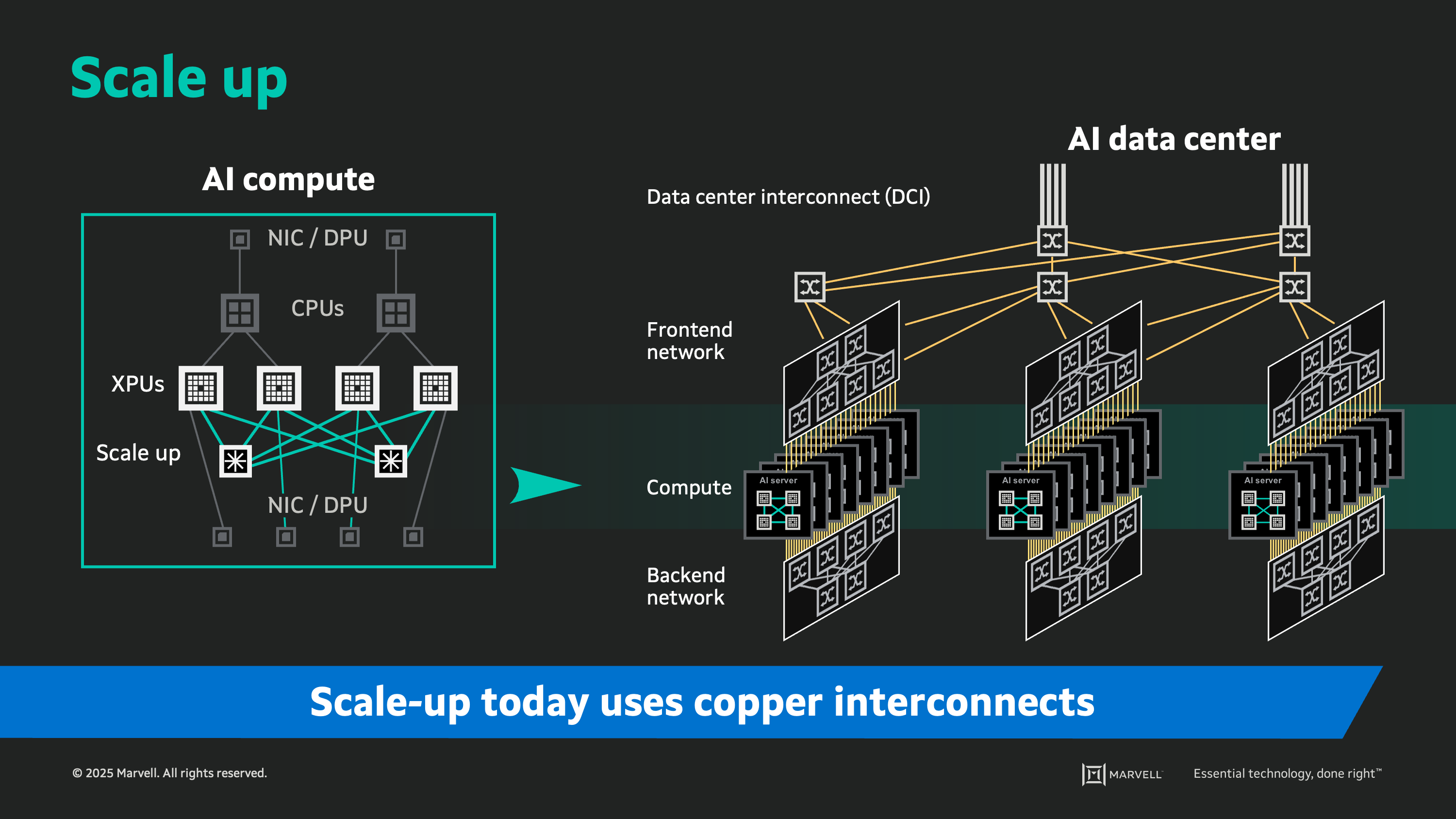
Scale up refers to the interconnect network closest to the GPU or XPU. In the earliest GPU approaches, scale up was literally a back-to-back interface enabling two chips to behave as one larger element. This has evolved to networked interconnects enabling tens or hundreds of processors. The key point is that scale-up elements must appear as a single computer from the perspective of the software. As such, the interconnect must be extremely reliable and should introduce the lowest possible delay. Because the size of the scale-up domain is small, devices can be placed in close proximity. Following naturally from these design constraints (and because of them), most scale-up interconnects today are copper-based, offering sufficient bandwidth and performance for speeds up to 100 Gbps, with a transition to 200 Gbps in the near future.

Starting with a tray (<10 XPUs) inside the AI compute rack, passive copper traces connect compute elements and switches which offer the lowest power consumption and lowest total cost, but these traces reach a limit at the edge of the tray.

Moving from a tray to a rack (<100 XPUs), copper cables connect servers together within the rack. This can also be very efficient, low-power and low-cost, but has limited reach though is sufficient for 100 Gbps links. But as data rates increase to 200 Gbps, the links cannot reach the full span of the rack as the physical limits of copper are reached.
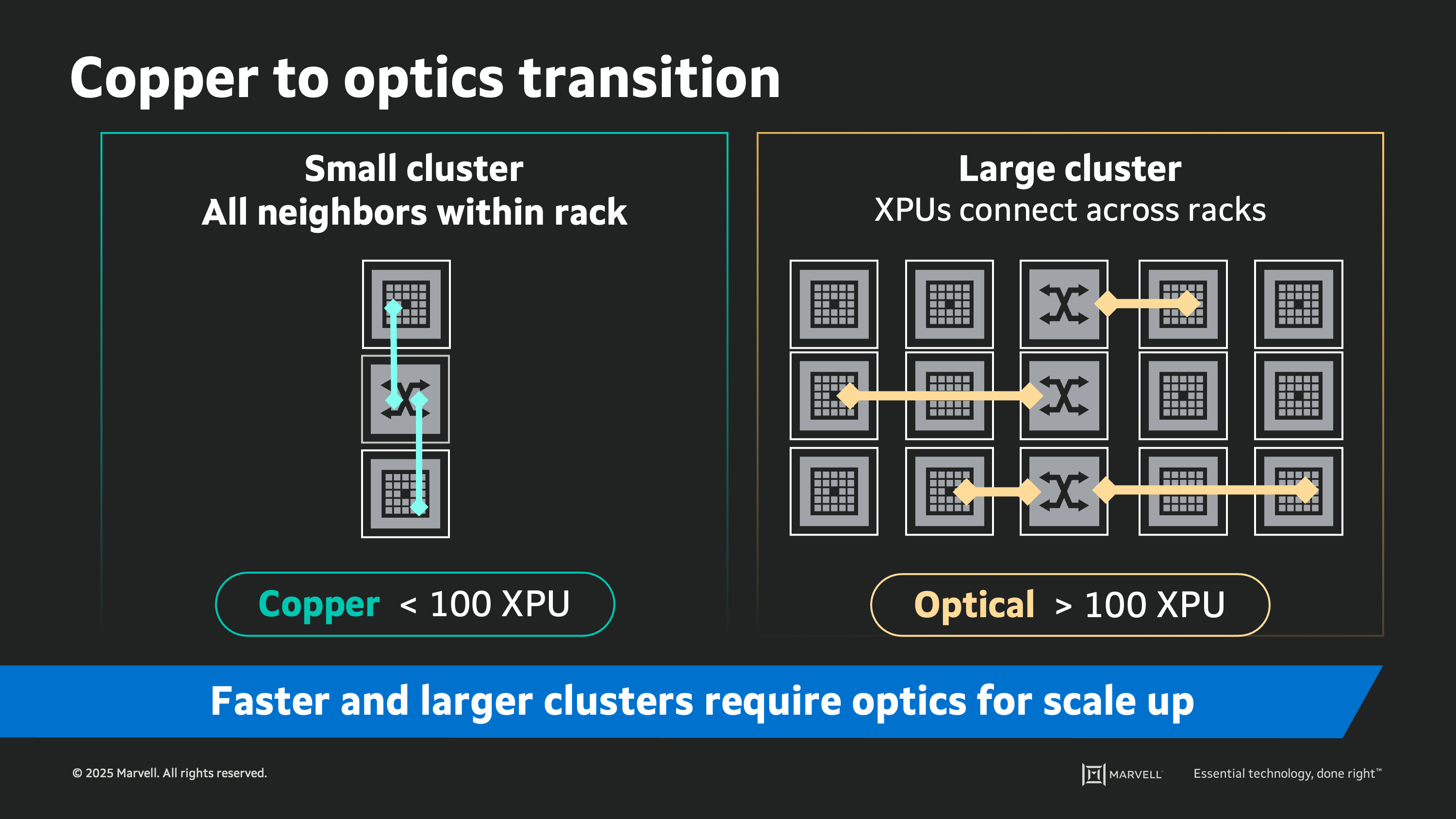
Driving to a larger scale-up domain can bring immense real-world performance benefits to an AI cloud design. Networking hundreds or thousands of scale-up elements available to a single compute task is clearly desirable. These larger sizes could require scale-up clusters to expand beyond one rack and past the reach of copper interconnects. With a transition to row-scale clusters, a migration from copper to optical appears inevitable. The focus is on optimized optical implementations suitable for relatively short reaches (tens of meters) which minimize power and latency while maintaining the bandwidth and resiliency enabled by the copper links they replace. This is the entry point for integrated optics.
Integrated optics
The transition to optimized optical scale-up clusters brings a diversity of new interconnect options to consider.
Linear pluggable optics (LPO), such as Marvell’s recently announced 1.6 Tbps linear pluggable optics chipset, are designed to address next-generation short-reach optical, scale-up compute fabric connectivity requirements. This type of optimized optical solution is suitable for constrained applications within compute server rows. Linear pluggable optics maintain the modular form factor used elsewhere in the cloud network today but promise lower power consumption and lower latency by offloading much of the high-speed signal processing to the compute and switching chips they interconnect (similar to what is done with passive copper cabling). This approach requires tight co-design of the complete system at the rack level, with detailed signal analysis spanning the compute and switching ICs, all circuit boards, connectors, fiber optic cabling, and the modules themselves. The low power and latency are achieved through a “finely tuned” approach, making the optical links a part of the AI server itself.
Noting the tight co-design requirements of LPO, we quickly see an opportunity to bring the optical links further within the system, eliminating the pluggable module in favor of direct-mounting the optical engine within the system. This is known as near-packaged optics (NPO) or on-board optics (OBO). This approach shortens the electrical trace length from the GPU or XPU to the optical engine. Whereas for LPO, electrical signals may travel for 300mm before converting to the optical domain, in NPO/OBO the signals may travel for 100mm or less. This can constrain and simplify the design of the system while further reducing power consumption.
The ultimate solution to optimized, integrated, optical interconnects for scale-up networks is co-packaged optics (CPO). This enables an XPU to be built without electrical interconnects, and all high-speed links leave the package directly over fiber-optic links. In the CPO model, high-speed digital signals originate in the electrical domain but are converted to the optical domain before leaving the package of the chip. Depending on the implementation, the electrical signals can travel from less than 1mm to approximately 20mm. This package-level integrated design enables tight co-design of the electrical and optical circuitry, which can enable higher reliability and more predictable performance than system-level integrated solutions. It also offers opportunities to further optimize the implementation for lower power consumption and lower latency.
Integrated optics solutions are ideal for scale-up networks seeking to expand beyond the reach constraints of copper while retaining its best attributes such as low power consumption, low latency, cost efficiency, and a compact form factor. As scale-up networks expand to 1,000K XPU clusters, we anticipate integrated optics will gradually replace today's passive copper interconnects, creating new market opportunities for the industry’s optical interconnect specialists.

Marvell 6.4T 3D silicon photonics light engine
At OFC 2024, Marvell demonstrated the industry’s first silicon photonics light engine to integrate high speed 200 Gbps optical interfaces in a compact form factor suitable for in-package integrated designs. The Marvell® 3D Silicon Photonics Light Engine integrates 32 channels of electrical and optical interfaces employing standards-based optical signaling, hundreds of components such as modulators, photodetectors, modulator drivers, transimpedance amplifiers, microcontrollers, and a host of other passive components in a compact engine approximately the size of a U.S. 25-cent coin. The light engine is a modular design, a building block that could be employed in XPU or other devices to provide high-speed connectivity directly from the package over fiber-optic links.
The Marvell technology is designed to enable co-packaged optics system evaluations for AI scale-up applications. It is available to Marvell prospective customers who are evaluating next-generation high-performance XPU (enabling 25.2 Tbps) and scale-up fabric elements (enabling 51.2 Tbps), as well as frontend NICs/DPU with integrated optics (enabling 6.4 to 12.8 Tbps). We anticipate a multi-year cycle of trial system development and testing of CPO system designs working in partnership with the manufacturing ecosystem and with hyperscale customers.
Silicon photonics: the technology enabling co-packaged optics
The move towards integrated optics is made possible by the rapid advances in silicon photonics technology over the last two decades. Silicon photonics enables large numbers of optical components to be integrated on a single silicon device, using photolithography processes like a traditional electronic integrated circuit. This enables a compact, highly integrated light engine like the Marvell device, with a large quantity of active optical elements on a single silicon die.
The Marvell device applies silicon photonics know-how gained from delivering optical interconnect solutions at the other end of the data center: for the long fiber links interconnecting data centers. For more than eight years, Marvell has delivered silicon photonics technology for successive generations of data center optical modules used in long-haul interconnects between data centers. Marvell silicon photonics devices have logged over 10 billion field hours at top hyperscalers. Marvell has used this expertise to create its CPO architecture for emerging use cases in XPU scale-up connectivity.

The tipping point for CPO
For many observers of technology transitions in the cloud data center, there is a tendency to assume that an emerging technology like CPO will rapidly change the landscape. However, to achieve broad adoption, CPO must first demonstrate its suitability for high-volume manufacturing and reliability in large-scale AI compute applications. We see seven key factors key to achieving high-scale CPO deployment.
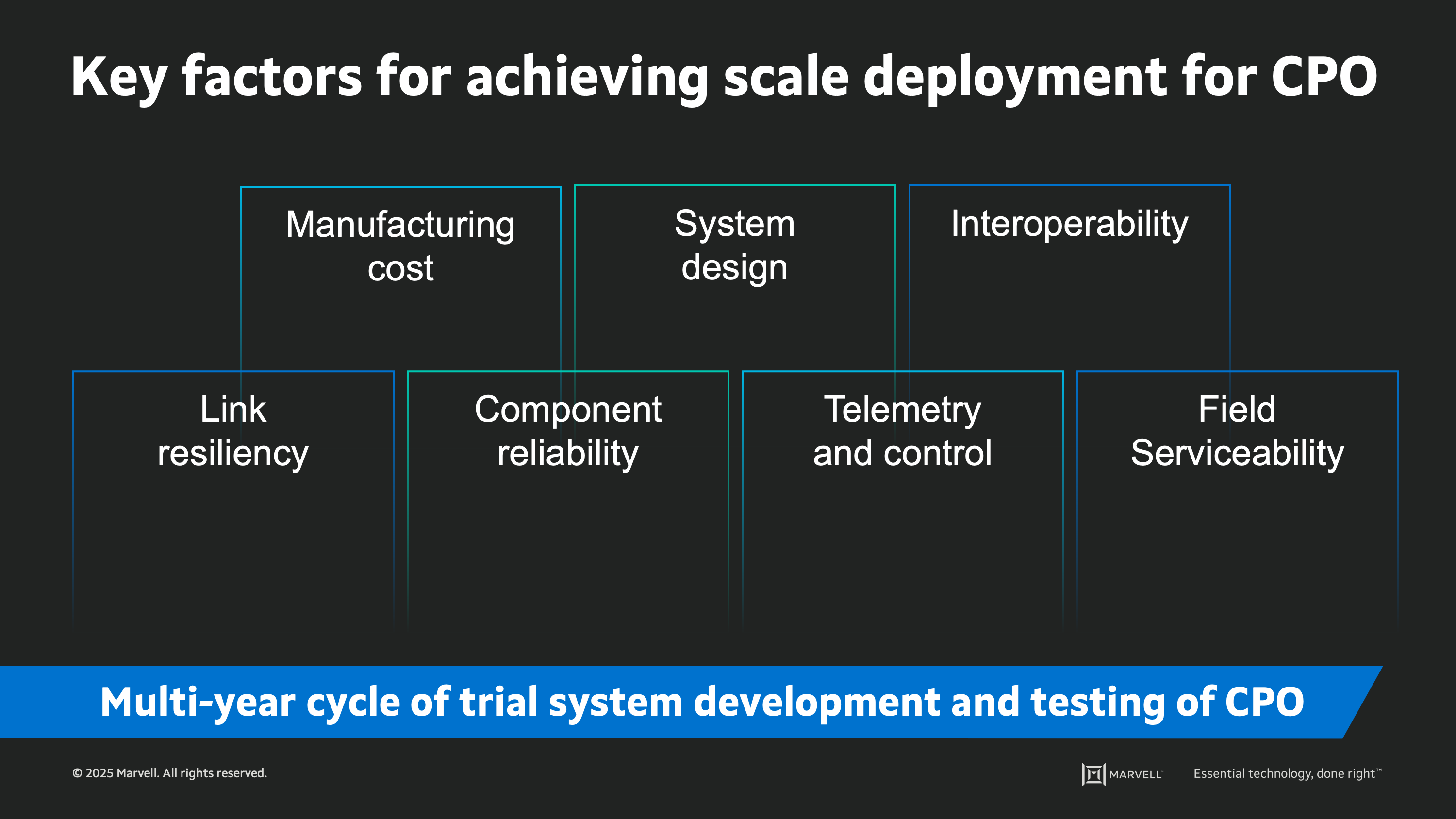
We anticipate a multi-year cycle of trial system development and testing of CPO approaches as equipment manufacturers and network designers work to qualify integrated optics against these seven factors. In parallel, CPO technology will continue to advance, further increasing its advantages for power consumption and latency. As both these efforts progress, we expect an eventual tipping point where the benefits of CPO have outrun legacy technologies, and CPO has demonstrated viability for deployment at scale.
Scale-out interconnects
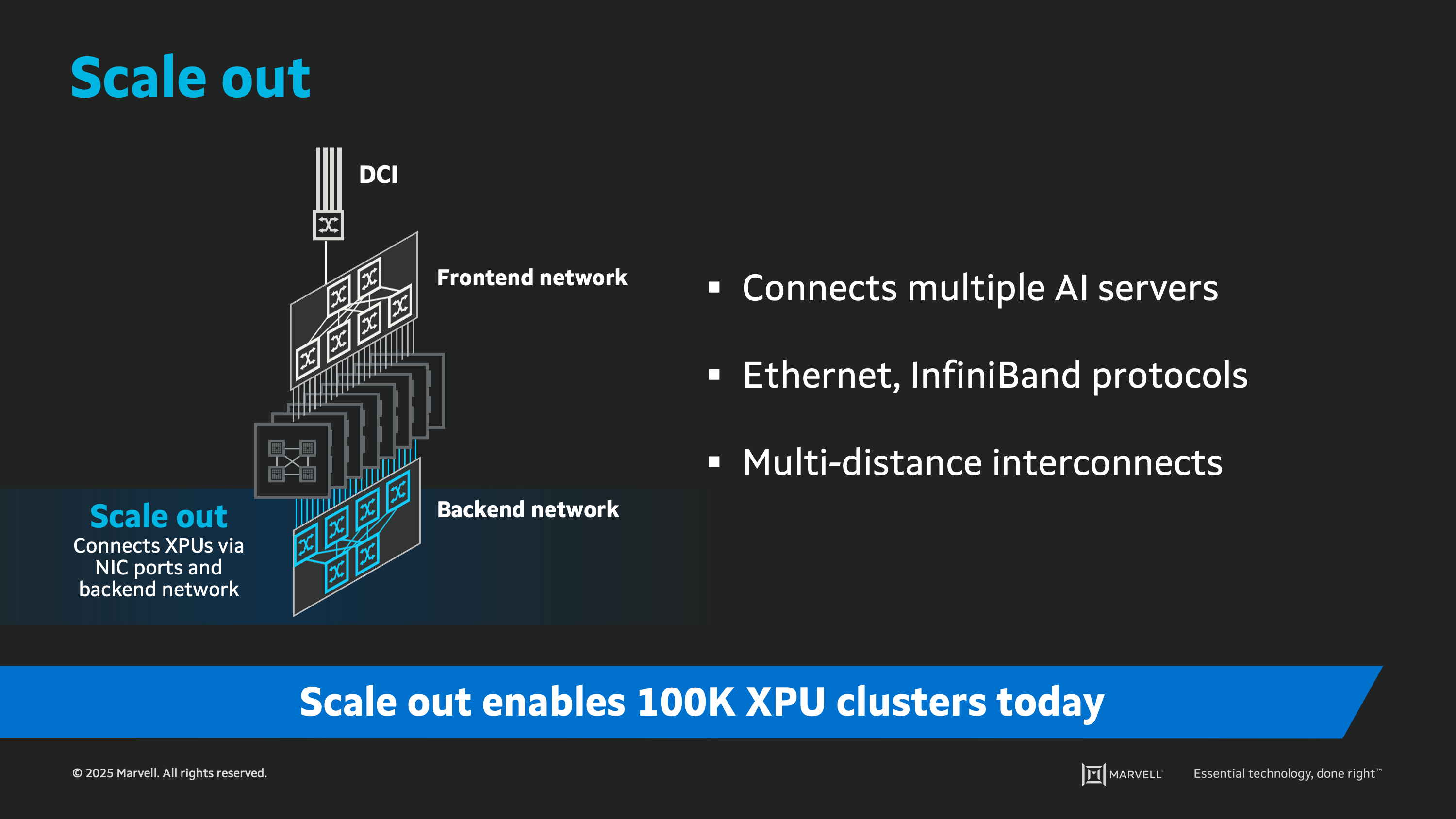
Scale out refers to the expansive AI interconnect network enabling clusters of ten thousand processors or more. Unlike in scale-up networking where the clustered processors appear as a single computer to the software, scale-out entails explicit parallel processing, where a task is split across multiple compute resources. Scale out networks typically use standard networking protocols such as InfiniBand or Ethernet and are designed to handle communications across larger distances within the data infrastructure. Often the scale-out network is comprised of multiple layers of switches, with the first tier of switches connecting to the compute endpoints, and the second and third tiers providing connectivity among the layer of switches below. The majority of scale-out interconnects today are optical, with passive copper cables sometimes used closer to the edge of the network if placement constraints allow. Since we are talking about networks of massive scale, reliability, scalability and serviceability are essential. Interconnects for scale out need to be highly resilient, plug and play, backward and forward compatible, serviceable and interoperable, providing very high bandwidth and long reach suitable for connecting many racks and many rows of compute resources. Scale-out networks deliver per-port speeds from 400 Gbps to 800 Gbps, extending to 1.6 Tbps and faster in the future.
Optical interconnects in AI scale out networks

Optical digital signal processors (DSPs), such as Marvell PAM4 optical DSP products, power the optical interconnects inside the world’s cloud and AI data centers, and support both Ethernet and InfiniBand architectures. With increasing demands for training, inference and cloud computing, operators must quickly scale out their networks with reliable, low-latency, high-bandwidth connectivity.
Marvell announced Ara, the industry’s first 3nm PAM4 optical DSP, which builds on six generations of Marvell leadership in PAM4 optical DSP technology. It integrates eight 200 Gbps electrical lanes to the host and eight 200 Gbps optical lanes, enabling 1.6 Tbps in a compact, standardized module form factor. Leveraging 3nm technology and laser driver integration, Ara reduces module design complexity, power consumption and cost, setting a new benchmark for next-generation AI and cloud infrastructure.

Coherent-lite technology, as applied to the Marvell® Aquila coherent-lite optical DSP, for example, is designed for high-bandwidth optical connectivity within campus networks, spanning distances from 2 to 20 kilometers. It offers power and latency optimization, making it ideal for connecting individual buildings in large AI data center campuses. This technology bridges the gap between short-reach interconnects and long-haul coherent solutions, providing efficient and reliable data transmission.
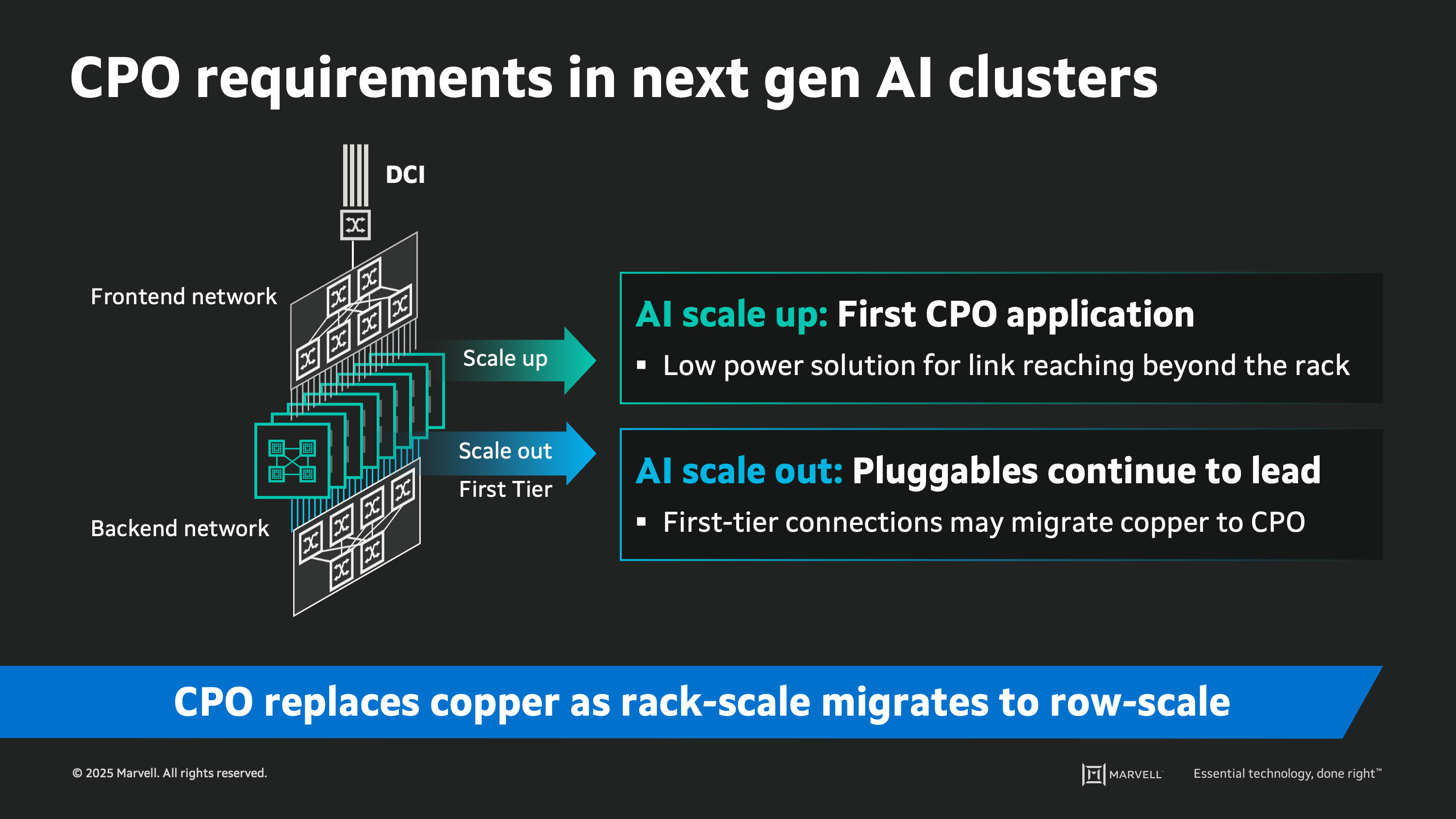
CPO for AI scale out
The majority of AI scale-out networks are based on optical interconnects, with passive copper sometimes used in the edge of the network closer to the compute accelerators. For these copper links, the considerations for integrated optics are similar to the considerations for a scale-up network. However, moving towards the outer tiers of the scale-out network (where optics are already used today), the considerations for reach, interoperability, resiliency, and performance will favor continued use of the pluggable DSP-based optics solutions. The tipping point for broad adoption of CPO in scale out will likely be when it can demonstrate its suitability for high-volume manufacturing and reliability. In the meantime, CPO in scale out is likely to be used for limited, low-volume use cases.
Data center interconnect (DCI)
Outside of the scale-out network, data center operators use high bandwidth fiber-optic links to provide high bandwidth connections between data center sites. These long-haul links can traverse long distances and are in many ways similar to the backbone links of the internet. For this portion of the network, known as data center interconnect (DCI), fiber is less plentiful than in the data center, so operators focus on maximizing the data transported on each fiber. Coherent ZR optics enables this ultra-high density, long reach optical communication by combining advanced modulation techniques with dense wavelength division multiplexing (DWDM), efficiently packing data and maximizing bits per wavelength. DWDM further enhances bandwidth utilization by multiplexing multiple wavelengths onto a single fiber.

A pioneer in DCI pluggable modules, Marvell introduced the industry’s first DCI pluggable COLORZ® 100 QSFP module in 2017 followed by the industry’s first 400G ZR/ZR+ QSFP-DD, COLORZ® 400, now both in volume production and widely deployed. In 2023 Marvell announced COLORZ® 800, the industry's first 800 Gbps ZR/ZR+ coherent pluggable optical module, capable of connecting data centers up to 1,200 kilometers apart. These modules leverage the Marvell Orion coherent DSP and silicon photonics technology, offering significant benefits in scalability, energy efficiency, and operational simplicity.
Scaling out to multi-site AI clusters with coherent ZR optics
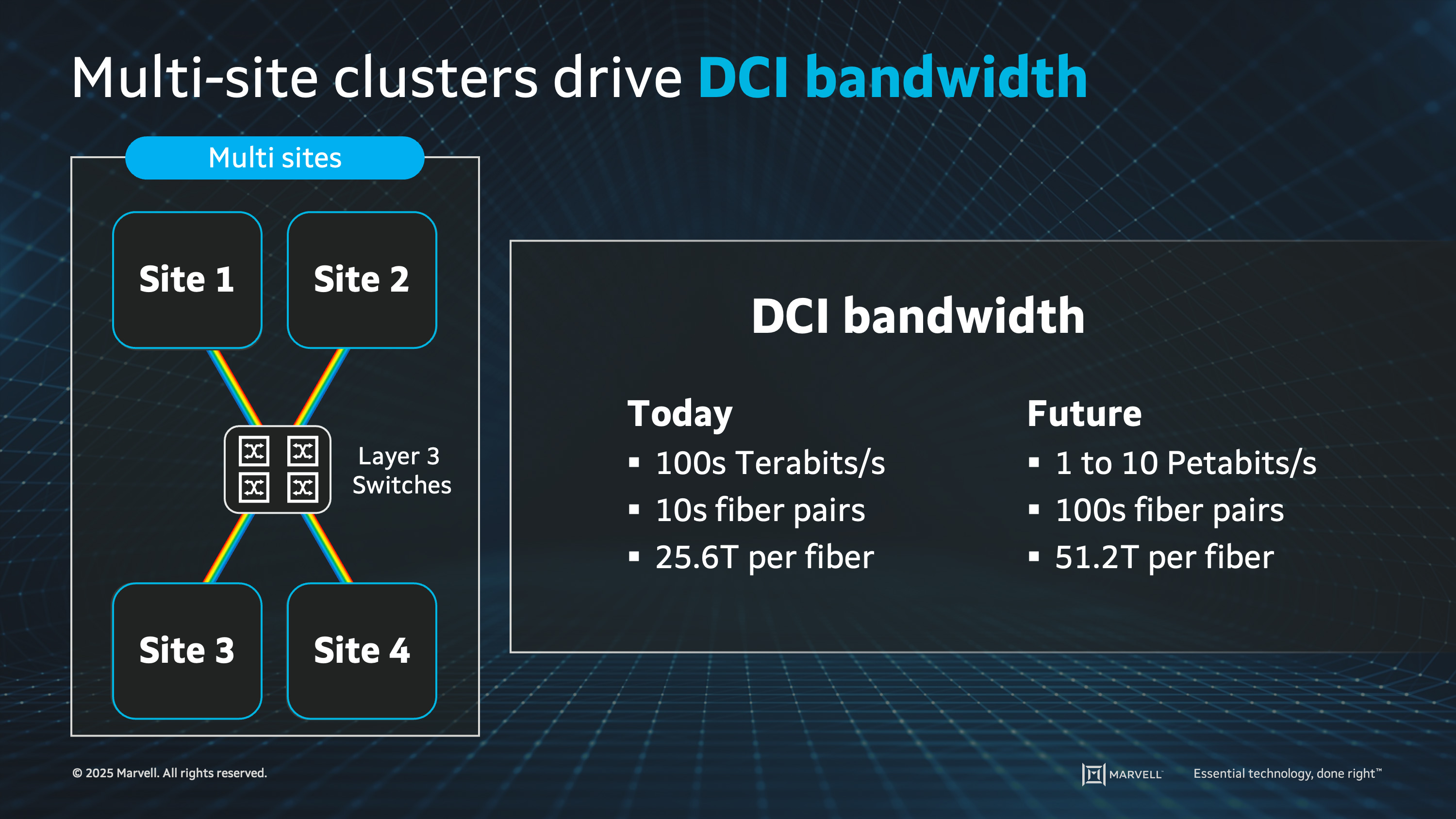
AI cluster sizes are already pushing the limits of what can be achieved within a single data center's physical footprint. This drives the need for multi-site AI clusters, which can distribute workloads across multiple data centers. Multi-site AI clusters require high-speed data transfer between locations, driving the need for more coherent ZR optics which provide the bandwidth needed for large-scale data processing and real-time AI applications. They enable seamless communication over various distances, support scalability, and ensure data integrity and redundancy.
The optical interconnect future is bright
The rapid expansion and increasing capacity of AI workloads are revolutionizing data movement and communications within networks. This evolution towards larger clusters with shorter compute times will drive the adoption of optics throughout AI networks. A diversity of optical technologies will continue to expand, each designed to address the specific application for every part of the network. Marvell is laser-focused on the development and integration of cutting-edge optical technologies and well-positioned to drive innovation for the continuously evolving demands of accelerated AI infrastructure.
It's becoming clear that optics will illuminate the future landscape for AI interconnects.
1. Evolution of Memory Architecture, Proceedings of the IEEE August 2015
This blog contains forward-looking statements within the meaning of the federal securities laws that involve risks and uncertainties. Forward-looking statements include, without limitation, any statement that may predict, forecast, indicate or imply future events or achievements. Actual events or results may differ materially from those contemplated in this blog. Forward-looking statements are only predictions and are subject to risks, uncertainties and assumptions that are difficult to predict, including those described in the “Risk Factors” section of our Annual Reports on Form 10-K, Quarterly Reports on Form 10-Q and other documents filed by us from time to time with the SEC. Forward-looking statements speak only as of the date they are made. Readers are cautioned not to put undue reliance on forward-looking statements, and no person assumes any obligation to update or revise any such forward-looking statements, whether as a result of new information, future events or otherwise.
Tags: AI, data center interconnect
