
While CXL technology was originally developed for general-purpose cloud servers, it is now emerging as a key enabler for boosting the performance and ROI of AI infrastructure.
The logic is straightforward. Training and inference require rapid access to massive amounts of data. However, the memory channels on today’s XPUs and CPUs struggle to keep pace, creating the so-called “memory wall” that slows processing. CXL breaks this bottleneck by leveraging available PCIe ports to deliver additional memory bandwidth, expand memory capacity and, in some cases, integrate near-memory processors. As an added advantage, CXL provides these benefits at a lower cost and lower power profile than the usual way of adding more processors.
To showcase these benefits, Marvell conducted benchmark tests across multiple use cases to demonstrate how CXL technology can elevate AI performance.
In December, Marvell and its partners showed how Marvell® StructeraTM A CXL compute accelerators can reduce the time required for vector searches used to analyze unstructured data within documents by more than 5x.
Here’s another one: CXL is deployed to lower latency.
Lower Latency? Through CXL?
At first glance, lower latency and CXL might seem contradictory. Memory connected through a CXL device sits farther from the processor than memory connected via local memory channels. With standard CXL devices, this typically results in higher latency between CXL memory and the primary processor.

Marvell Structera A CXL memory accelerator boards with and without heat sinks.
The Marvell Structera A memory accelerator, however, contains a feature not found in other CXL devices: 16 Arm Neoverse server processors. Combined with capacity for up to 4TB of DDR4 and 200Tbps of memory bandwidth, Structera A operates as a “server-within-a server,” performing tasks like processing deep learning recommendation models (DLRM) for the primary XPU or CPU. Because these processors are tightly coupled with their own memory pool, distance and latency are reduced.
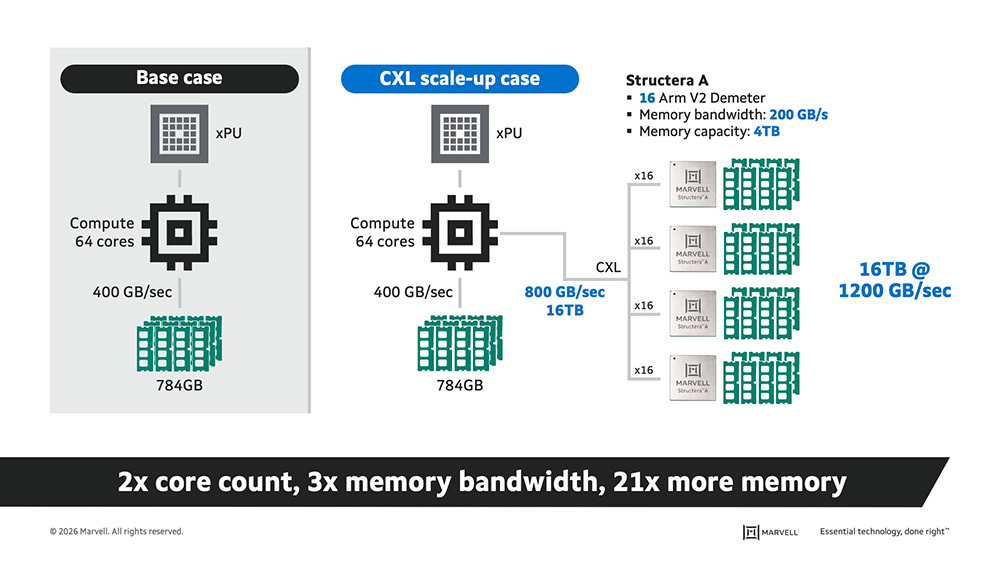
The diagram shows a standard server compared to another with four Structera A devices. Together, these devices add 64 processor cores, up to 16TB of DDR5 DRAM and 1200 GB/second of memory bandwidth.
As an added advantage, multiple Structera A boards can be installed in a single server to further increase memory capacity and bandwidth; the only real constraint is the number of available PCIe slots.
The CPU Is Open for Business
In the benchmark test, vector searches—used to locate unstructured data within documents and other media—were conducted on two systems:
The goal was two-fold:
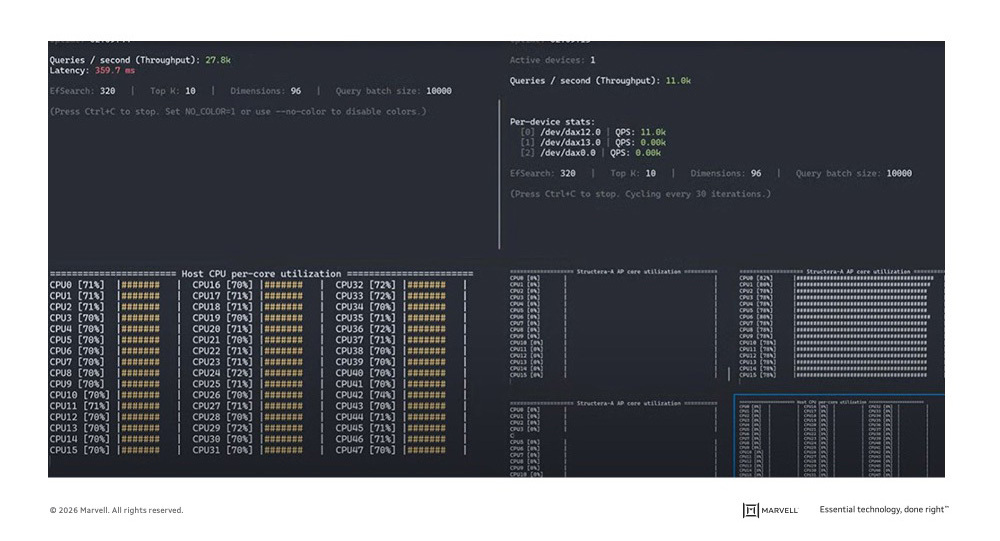
With only a single Structera A board running (left), the traditional processor comes out ahead, handling 27.8K queries per second with 359 milliseconds (ms) latency (right). In comparison, the single Structera device processes 11K queries per second.
But look at what happens when three boards come online. The Structera A-enhanced system reaches 35.9K queries per second at a latency of 278.9 ms, with all processing occurring near memory with the Structera A embedded server processors. By contrast, the control system tops out at 27.8K queries per second at a longer latency of 359.9 ms. That’s a 29% increase of queries per second being answered at a 22.5% lower latency.
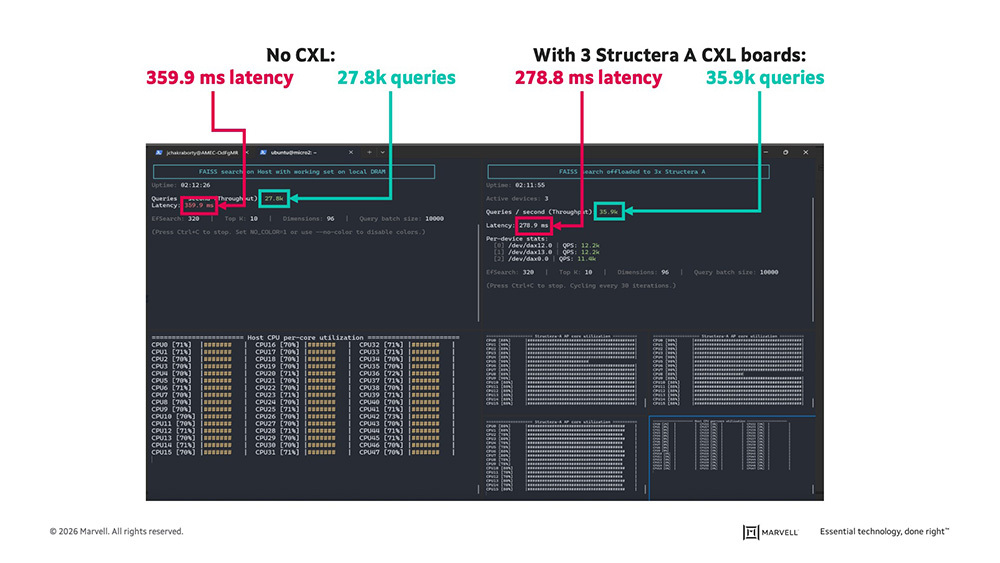
Note again CPU utilization. The CPU in the CXL-less processor is utilized 70 to 71% of the time (left). In the CPU in the CXL-enhanced system, one core hits 2% while another goes to 4% (see zoomed-in image below) with the rest resting at zero. Freeing the host CPU effectively gives service providers more capacity to sell additional services.

The CXL Renaissance
In 2025, networking was touted as the primary bottleneck to greater computing performance. By 2026, the focus has shifted to memory. CXL provides developers with a clear path forward by enabling the addition of large and often the most cost-effective memory pools to existing servers. As the industry explores what’s possible with this technology, expect to see more use cases emerge as the market uncovers new ways to unlock performance gains.

Patrick Kennedy of ServeTheHome runs the benchmarks for Structera X and Structera A in this video.
# # #
This blog contains forward-looking statements within the meaning of the federal securities laws that involve risks and uncertainties. Forward-looking statements include, without limitation, any statement that may predict, forecast, indicate or imply future events or achievements. Actual events or results may differ materially from those contemplated in this blog. Forward-looking statements are only predictions and are subject to risks, uncertainties and assumptions that are difficult to predict, including those described in the “Risk Factors” section of our Annual Reports on Form 10-K, Quarterly Reports on Form 10-Q and other documents filed by us from time to time with the SEC. Forward-looking statements speak only as of the date they are made. Readers are cautioned not to put undue reliance on forward-looking statements, and no person assumes any obligation to update or revise any such forward-looking statements, whether as a result of new information, future events or otherwise.
Tags: memory, AI, AI infrastructure, data centers
