Scaling AI infrastructure is a foundational challenge for modern data centers. As AI models grow in size and complexity, infrastructure must scale across compute, memory, connectivity, power, and physical footprint together. Understanding how scale operates across these domains is essential for designing AI systems that remain efficient, reliable and sustainable.
The industry is rapidly transitioning from 800G to 1.6T connectivity to support the exponential growth of AI workloads.

Scaling AI infrastructure refers to the architectural approaches used to expand AI system performance, capacity, and reach while maintaining efficiency, reliability, and predictable operation. Unlike traditional enterprise infrastructure, AI systems require tightly coordinated compute, memory, and connectivity as they grow, because performance is increasingly determined by how these resources work together rather than by individual components.
In this context, scaling AI infrastructure is not limited to adding more servers or accelerators. It describes how AI systems evolve across multiple physical and logical domains as workloads, model sizes, and deployment footprints increase.
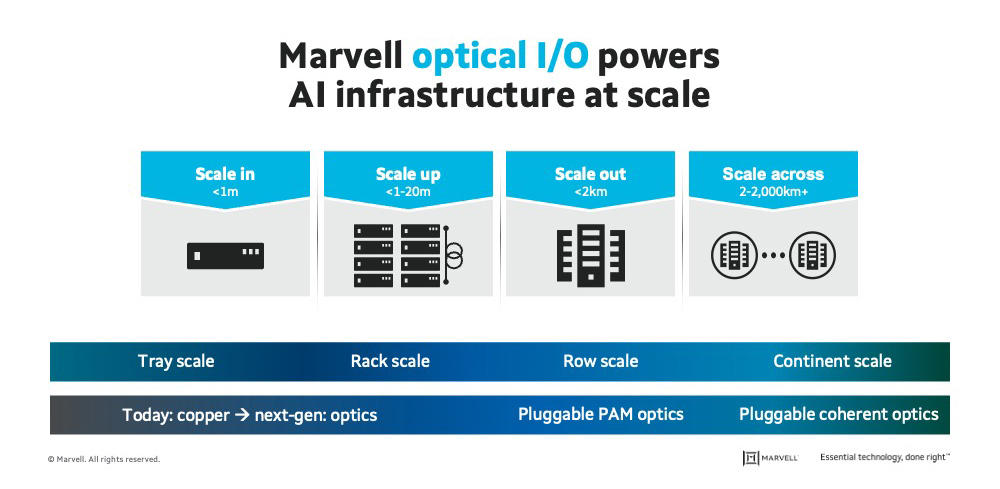 AI infrastructure scales across multiple physical domains—from package and rack to data center and campus—each with distinct connectivity requirements.
AI infrastructure scales across multiple physical domains—from package and rack to data center and campus—each with distinct connectivity requirements.
AI infrastructure introduces challenges that traditional enterprise architectures were never designed to handle. Accelerators must operate as coordinated systems, memory bandwidth must scale with compute density, and data movement increasingly determines overall system performance and power efficiency.
As a result, scaling AI systems is inherently multidimensional. It spans the following domains:
Each of these dimensions represents a distinct aspect of scale that influences how AI infrastructure is designed, connected, powered, and operated. Together, they establish the scope for understanding scale in AI infrastructure and set the foundation for scale in, scale up, scale out, and scale across architectures discussed in the sections that follow.
Traditional enterprise architectures were not designed to support modern AI workloads. AI accelerators must function as coordinated systems, memory bandwidth must scale with compute density, and data movement increasingly determines overall performance and power efficiency.
As AI systems grow, additional constraints emerge, including power availability, cooling capacity, physical footprint, and utilization efficiency. Scaling models provide a structured way to understand and manage these constraints across the infrastructure stack.
Core Concepts
Core Components
Scale in focuses on increasing capability within the smallest deployable unit, typically a chip, package, or individual server node.
Enabled by
Primary benefits
Primary constraints
 Silicon photonics enables highly integrated light engines, forming the foundation for scale-out and scale-across AI architectures.
Silicon photonics enables highly integrated light engines, forming the foundation for scale-out and scale-across AI architectures.
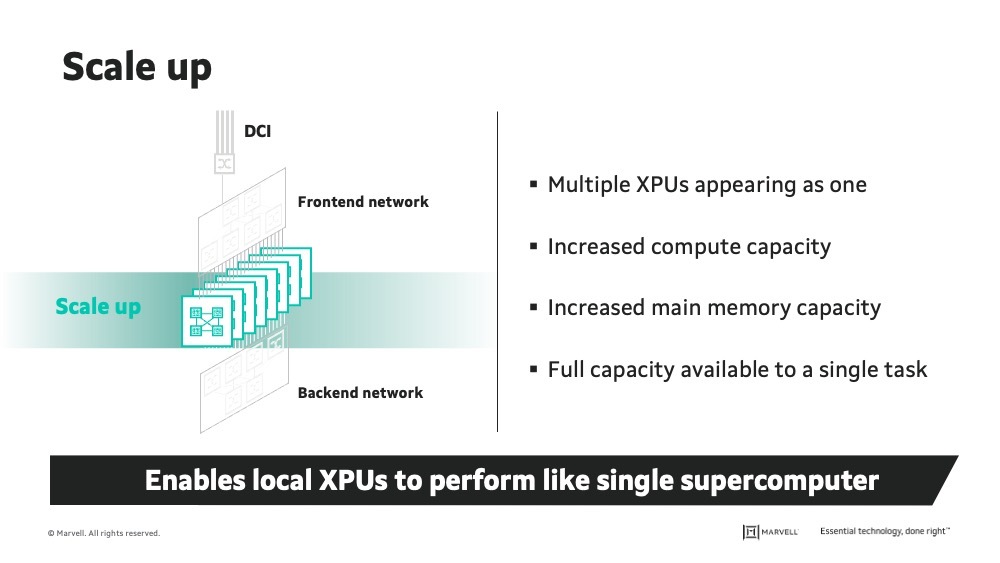
Scale up expands capacity by tightly connecting multiple compute and memory resources so they behave as a single logical system.
Enabled by
Primary benefits
Primary constraints
Typical scope
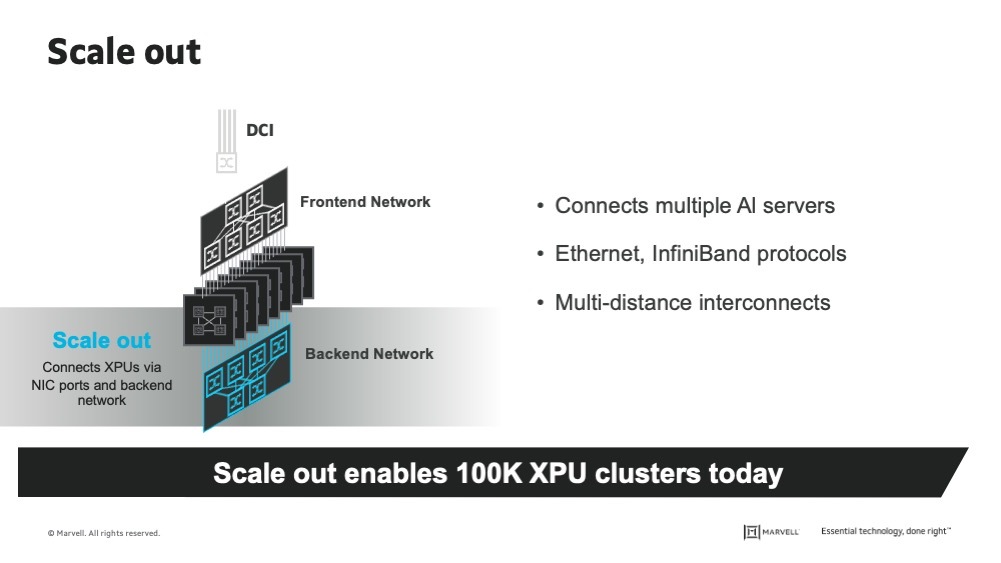
Scale out connects multiple scale up systems into large clusters where workloads are distributed across nodes. Emerging architectures such as optical circuit switching are enabling more efficient, low-latency communication across large-scale AI clusters.
Enabled by
Primary benefits
Primary constraints
Typical scope
Scale across extends AI infrastructure across multiple data centers, campuses, or geographic regions.
Enabled by
Primary benefits
Primary constraints
Typical scope
AI scaling decisions require balancing latency versus reach, bandwidth versus power consumption, integration versus flexibility, and capital expenditure versus operational cost. These tradeoffs vary across scaling models and must be evaluated holistically across silicon, systems, and networks.
Use when:
Effective AI infrastructure design aligns scaling strategies with workload behavior and operational constraints.
AI infrastructure is shaped by platforms rather than individual components. Compute, memory, packaging, networking, optics, power delivery, and cooling all influence how AI systems scale and how different scaling models are implemented in practice.
As AI workloads evolve, several ecosystem level trends are becoming more prominent. Platform level co design is increasingly required to balance performance, power, and cost. Customization is extending beyond accelerators into switches, interconnect, and system level silicon. Open standards and interoperable ecosystems are playing a larger role in enabling scalable and flexible AI infrastructure.
Together, these factors determine how scale in, scale up, scale out, and scale across architectures are realized across different deployment environments.
At the scale-in and scale-up layers, AI infrastructure emphasizes dense integration, high-bandwidth connectivity, and low latency communication within nodes, packages, and racks. Platform technologies at this layer focus on electrical interconnect, signal processing, and tightly integrated silicon. Marvell delivers an end-to-end connectivity portfolio spanning die-to-die, optical, electrical, switching, and co-packaged technologies across scale-in, scale-up, scale-out, and scale-across architectures.
Scale In and Scale Up
At the scale in and scale up layers, AI infrastructure emphasizes dense integration, high bandwidth connectivity, and low latency communication within nodes, packages, and racks. Platform technologies at this layer focus on electrical interconnect, signal processing, and tightly integrated silicon.
Marvell platform examples at this layer include:
Scale Out
Scale-out architectures depend on scalable networking fabrics that support large clusters, complex traffic patterns, and high aggregate bandwidth across data centers.
Marvell platform examples at this layer include:
Scale Across
Scale across architectures extend AI infrastructure across campuses and geographic regions. These environments introduce longer reach requirements, increased sensitivity to latency, and more complex fault domains.
Marvell platform examples at this layer include:

Scaling AI infrastructure is a foundational challenge for modern data centers. Scale in, scale up, scale out, and scale across provide a structured framework for understanding how AI systems expand across chips, nodes, data centers, and regions. As AI workloads continue to grow, future infrastructure will increasingly depend on advanced interconnect technologies, platform level co design, and holistic approaches that treat scale as a core architectural principle. To learn more, explore related resources or engage with your infrastructure planning teams.
Scaling AI infrastructure refers to expanding compute, memory, and connectivity in a coordinated way so AI systems maintain performance and efficiency as they grow.
Scale in increases capability within a single node, while scale up tightly connects multiple nodes to behave as one system.
Scale out expands AI systems within a data center, while scale across extends them across campuses or geographic regions.
Interconnect determines latency, bandwidth, power efficiency, and reach, which directly affect AI system performance at scale.
Large‑scale AI training typically combines scale in, scale up, scale out, and scale across models so that dense nodes, tightly coupled systems, large clusters, and multi‑site deployments can all be used together depending on model size and deployment constraints.
Power and cooling limits affect AI scaling by capping how much compute and networking can be added at a given location before performance, reliability, or operating costs become unacceptable. They restrict how much additional compute and networking can be deployed at a single site before scale‑across or more efficient designs are required, forcing architects to either improve per‑watt efficiency or distribute workloads across multiple data centers.
Yes. Most production AI systems combine multiple scaling models to balance performance, efficiency, and operational needs.
Network topology affects bandwidth availability, congestion, fault tolerance, and scalability across large AI clusters.
Optical interconnects enable higher bandwidth and longer reach than electrical connections, supporting scale out and scale across architectures.
We believe better partnerships help to build better technologies. Let’s connect and see what we can design together!
We will be in touch with you soon!