
Data centers are arguably the most important buildings in the world. Virtually everything we do—from ordinary business transactions to keeping in touch with relatives and friends—is accomplished, or at least assisted, by racks of equipment in large, low-slung facilities.
And whether they know it or not, your family and friends are causing data center operators to spend more money. But it’s for a good cause: it allows your family and friends (and you) to continue their voracious consumption, purchasing and sharing of every kind of content—via the cloud.
Of course, it’s not only the personal habits of your family and friends that are causing operators to spend. The enterprise is equally responsible. They’re collecting data like never before, storing it in data lakes and applying analytics and machine learning tools—both to improve user experience, via recommendations, for example, and to process and analyze that data for economic gain. This is on top of the relentless, expanding adoption of cloud services.
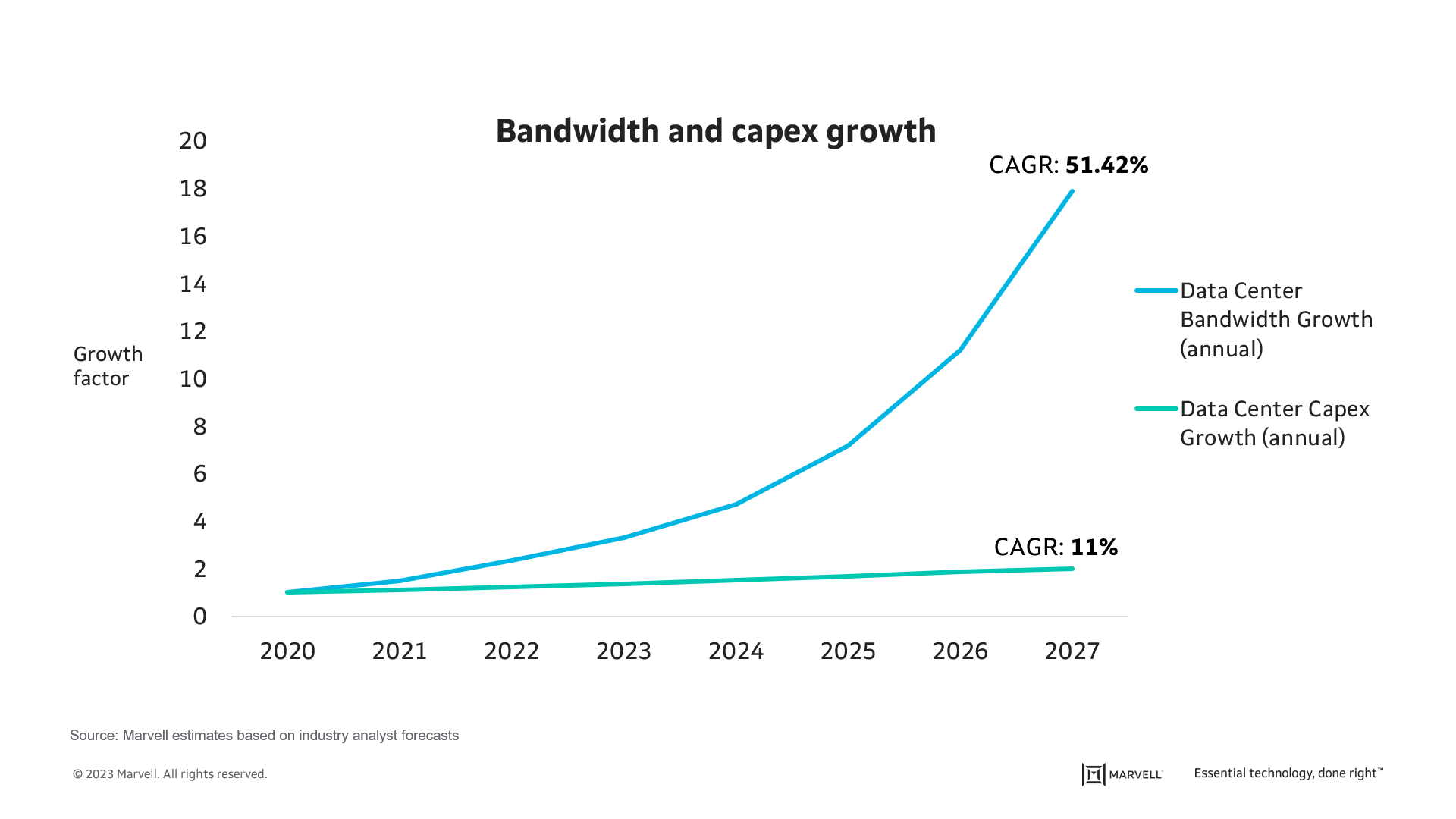
But this data center popularity is also a problem. As shown by the blue line below, analysts expect data center bandwidth to grow at more than 50% CAGR over the next five years. But look at the green line. CAPEX is slated to grow by only 11%, meaning that data center operators will have to squeeze far more work out of their facilities than ever before. If they can, we will see continued adoption of new technologies such as ChatGPT and wider adoption of initiatives such as medical health records. If not, costs will rise, and progress will slow.
So, what can operators do? We are, I believe, on the verge of a major retrofit of the underlying technologies for networking in data centers. And these changes will focus on three principles:
1. Greater power efficiency is mandatory
Data centers consume a lot of electricity.
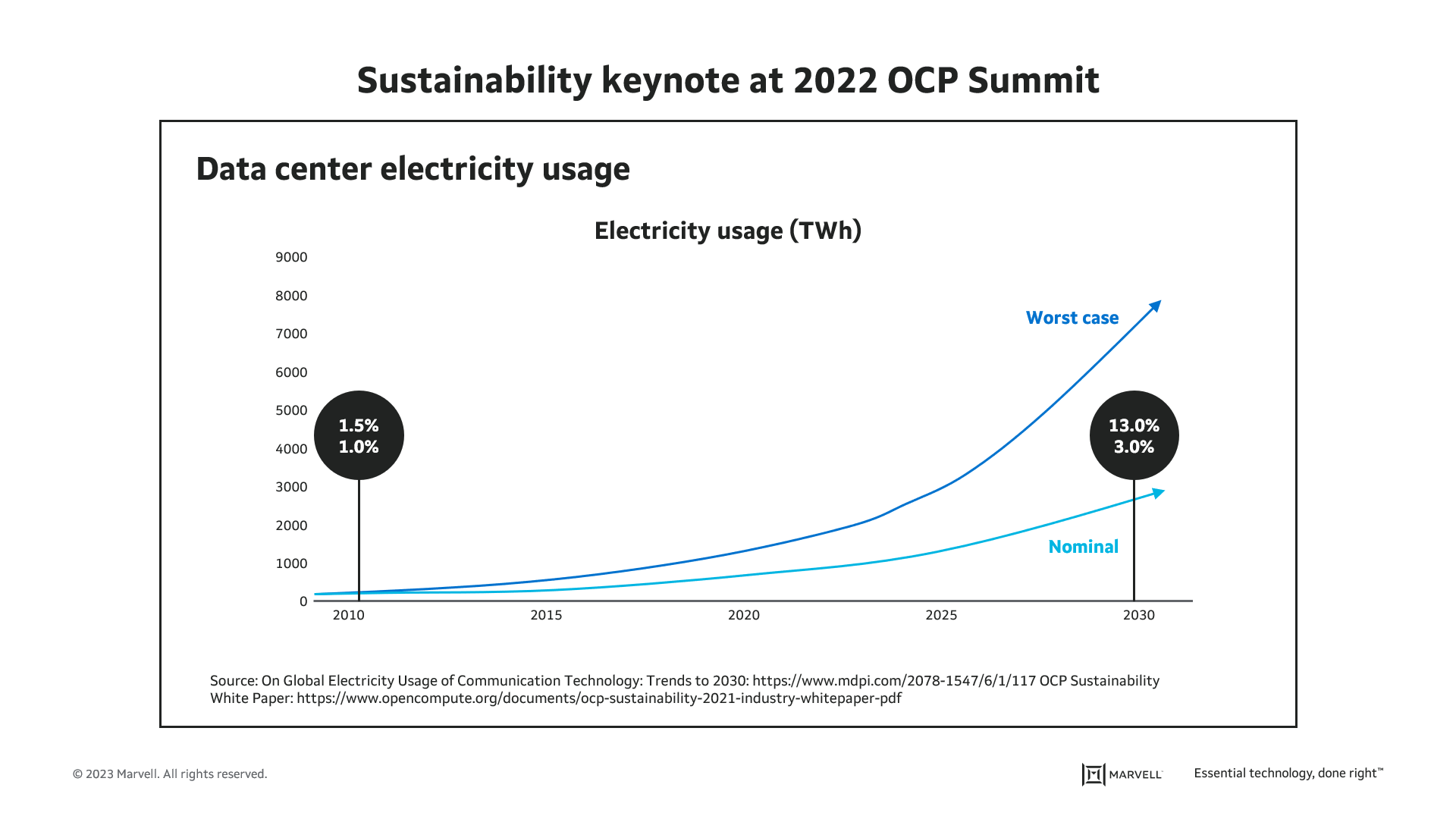
And while the data center share of worldwide electricity usage is low (1% to 1.5% in 2010), absolute consumption in specific locales is becoming problematic. Earlier this year, the Greater London Authority told real estate developers that a new housing project in West London may not be able to go forward until 2035 because data centers have taken all of the excess grid capacity.
As shown below, while remaining “low” as a share of worldwide usage, data center consumption is projected to increase that share, perhaps even into the double-digits. It’s no wonder data center operators are aiming to become carbon neutral or negative.
If we peer inside the walls of the data center, we can see that power consumption associated with networking is increasing its share of overall data center electricity usage, as presented by Microsoft at OCP 2022.
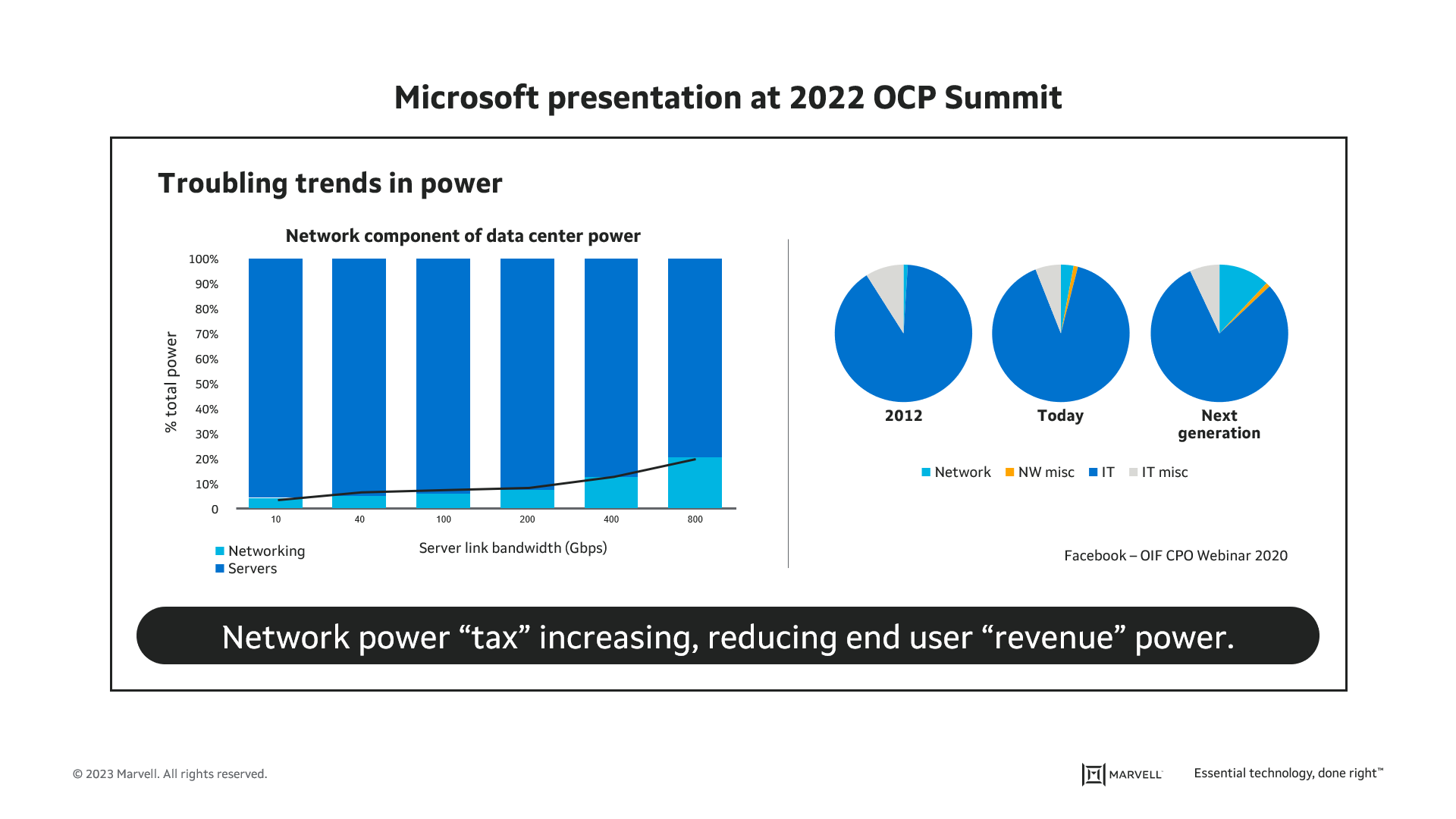
This is a problem for operators, as suggested at the bottom of the figure. Why? Because whereas networking does not always generate revenue, computing does. Power consumed by networking is power that would otherwise be available for revenue-generating servers and the applications that run on them. As described in Google’s keynote at OCP Summit in October 2022, a new class of custom silicon is needed to achieve improved networking power and cost efficiencies.
2. Time spent in networking must be reduced
Modern cloud-native applications are built on a distributed microservices architecture. Such an architecture results in high volumes of machine-to-machine traffic between containers or virtual machines (VMs) within racks, across racks and through multiple tiers of network switches. Each network hop adds latency, which increases the time required to complete a given computing job.
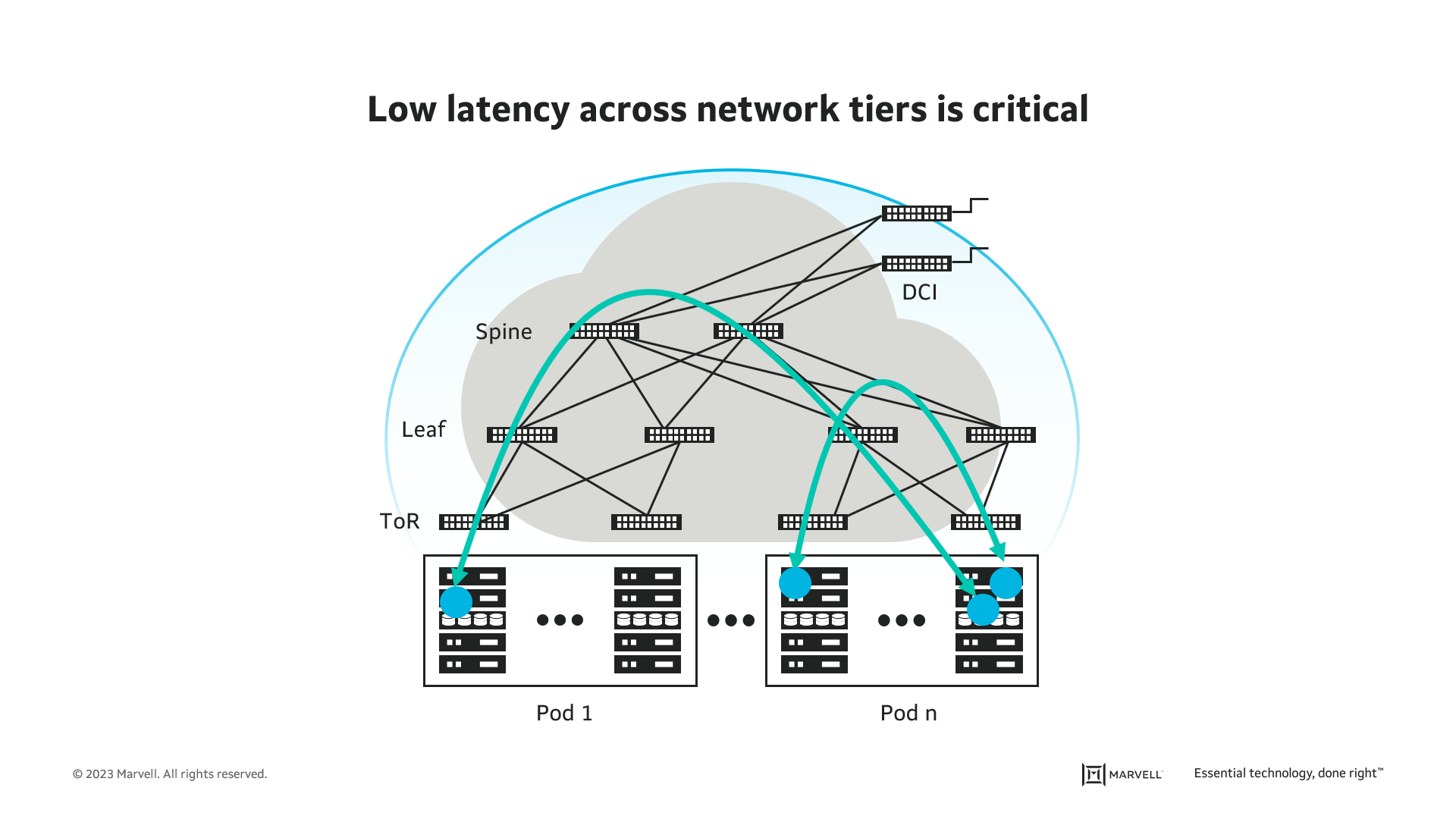
Given that the data center revenues improve with greater xPU utilization, any network latency detracts from revenue generation. This is true for cloud-native applications in general and even more pressing an issue for specific types of highly distributed applications.
Three such highly distributed applications are high performance computing (HPC), distributed databases (e.g., Cassandra, MapReduce) and machine learning (ML) training.
Large ML training models may have millions of parameters and, of course, massive training data sets. Training typically involves matrix multiplication across multiple GPU/ML nodes followed by the exchange of results (also known as gradient exchange) across these nodes. This process recurs until training results achieve the desired level of accuracy. As described above, such workloads by their nature spend a significant amount of time in networking.
At the OCP Summit in October 2022, Meta speaker Alexis Bjorlin highlighted the surprising percentage of time spent in networking for AI training workloads. In December 2022 at AWS re-Invent, Peter DeSantis specifically identified the network as an ML-training constraint. As both speakers show, the need is clear: lower latency networking.
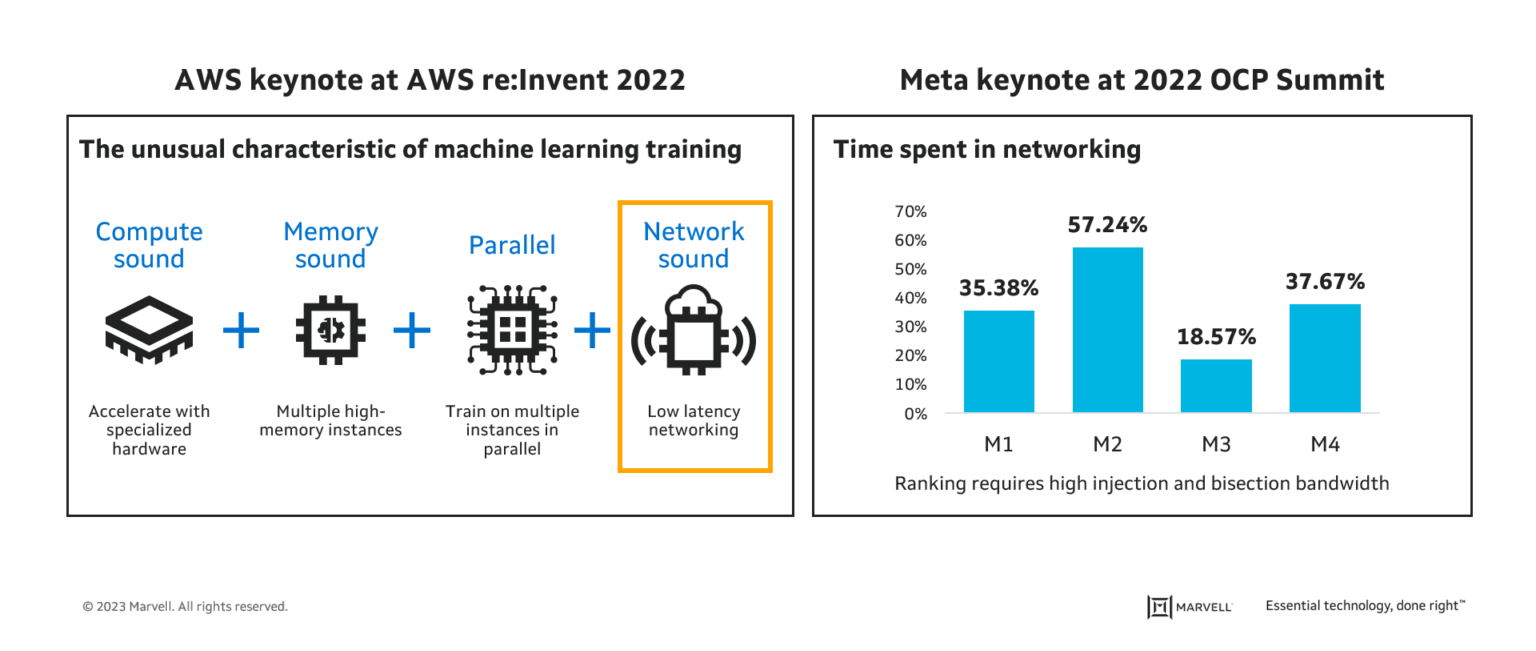
3. Telemetry data is critical for application availability
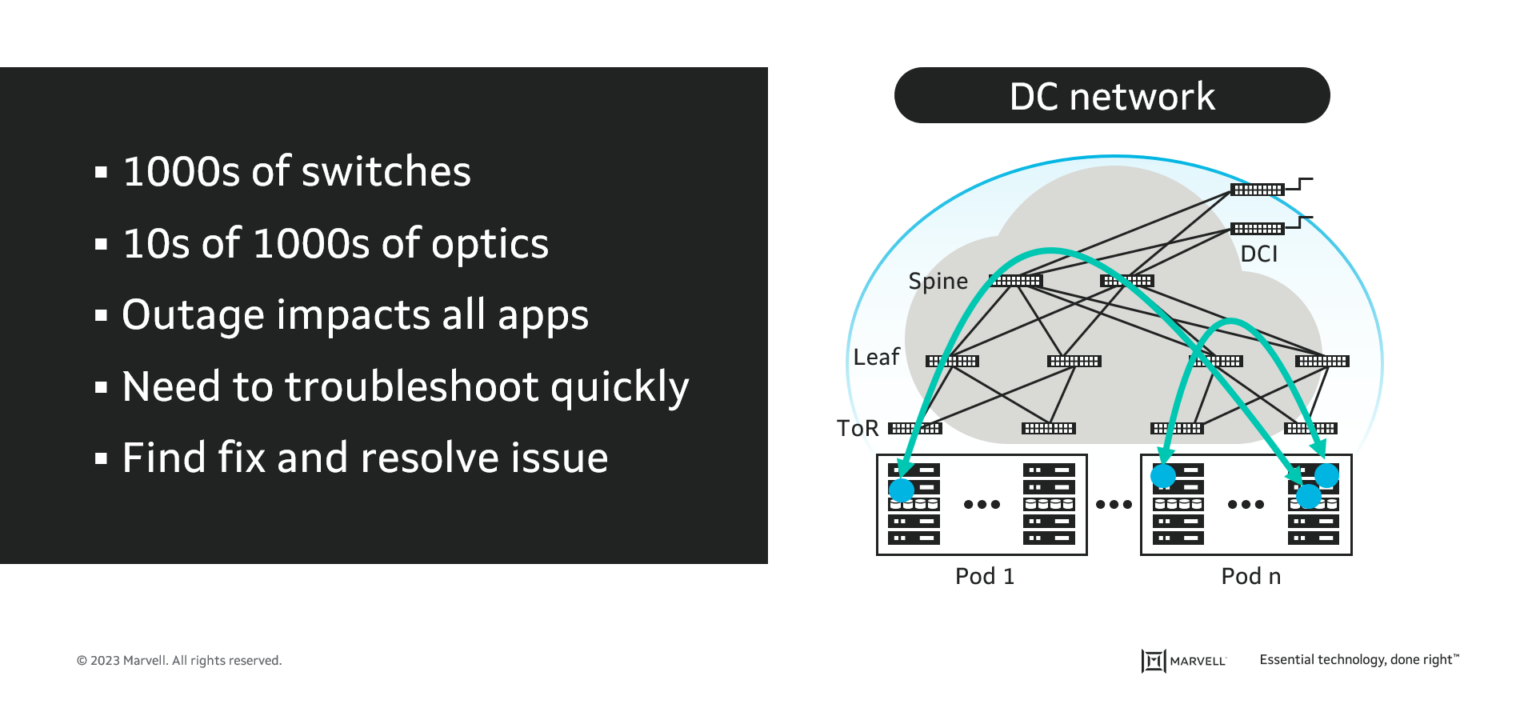
In a mega-scale data center, there are typically thousands of network switches and tens of thousands of optical modules connecting them. If a server fails, only applications running on that server are affected. By contrast, when a network module or switch fails, it can potentially impact every application running in the data center.
At this scale, troubleshooting is complex. Issues ultimately attributed to storage or servers may be initially misattributed to the network—which may be a reasonable assumption given the larger “blast radius” of a network switch outage.
But assumptions don’t help with root cause analysis. Data center operators require their equipment vendors to generate the telemetry data needed to troubleshoot, identify root causes and resolve issues quickly. Granular telemetry from network switches and optical modules is critical for simplifying operations, predicting performance degradation or component failure, and ensuring high availability.
What the next-generation data center network needs
And this is just the beginning. Even as application demand increases, the nature of the applications demanded is evolving. Architectures are becoming more distributed, and AI/ML is permeating every category of consumer and enterprise software.
Then, there’s the small matter of operations. Uptime is king. That means the network equipment needs to provide all the telemetry data needed to “find it and fix it fast.” And it means that next-gen networking equipment should not disrupt existing, well-oiled operational processes.
All these requirements must be instantiated by vendors in the products that move data: switches and optical modules. In Marvell’s case, that means switch chips and optical DSPs. More on that in the next post.
This blog contains forward-looking statements within the meaning of the federal securities laws that involve risks and uncertainties. Forward-looking statements include, without limitation, any statement that may predict, forecast, indicate or imply future events or achievements. Actual events or results may differ materially from those contemplated in this blog. Forward-looking statements speak only as of the date they are made. Readers are cautioned not to put undue reliance on forward-looking statements, and no person assumes any obligation to update or revise any such forward-looking statements, whether as a result of new information, future events or otherwise.
Tags: data centers, lower latency networking, network switches, networking for AI training workloads, networking in data centers, xPU utilization
